


在很多場景上,常需要判斷 A 是否在此集合裡面。
「某 A 郵箱,判斷是否在數十億垃圾郵箱列表中,來達到防止垃圾郵箱的訪問、註冊等等。」
如果我們在查找數據庫之前有做數據緩存,像是 redis 緩存之類的,假設黑客惡意大量訪問、發起大量請求。
不僅會造成緩存掛掉,還有數據庫掛掉
那就是知名的穿庫、緩存穿透問題。
四種方向
假設先不考慮緩存、資料庫掛掉的情境,我們可以想到以下幾個方向的處理方式:
將所有垃圾郵箱存到數據庫,直接進數據庫遍歷匹配。
用 HashSet 存儲所有垃圾郵箱,做到接近 O(1) 效率匹配。
用 MD5 算法或單向映射算法將垃圾郵箱轉換計算後,在透過HashSet 存儲, 保存的只有 MD5 計算後的固定位數。
用布隆過濾器(Bloom Filter),將所有垃圾郵箱透過多個 Hash 算法,映射到一個 bit 數組
方向一:
分析解釋:不管空間、時間。
這是最簡單的想法,保存完整垃圾郵箱
駭客攻擊:緩存、數據庫掛掉。
方向二:
分析解釋:不管空間,降低時間消耗
HashSet 是 java 的集合
Set 是最簡單的一種集合。集合中的物件不按特定的方式排序,並且沒有重復物件。
HashSet 按照哈希算法來存取集合中的物件,存取速度比較快
簡單講解算法,時間空間複雜度
O(n) 隨著 n 越大 O 也會跟著增大,又稱線性階
O(1) 則是不管 n 多大, O 永遠會是 1,又稱常數階
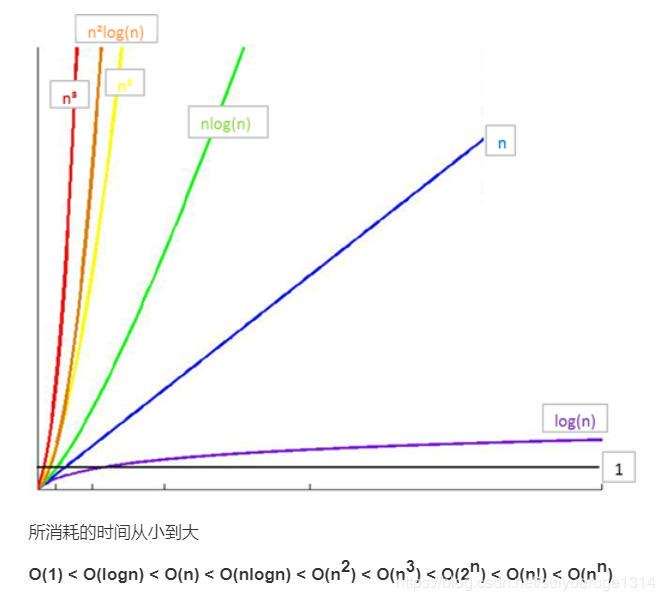
也是保存完整垃圾郵箱,要是字節數一多,會佔用幾百G 的空間內存。而透過剛剛的介紹,也知道 O(1) 查找效率最好,要是放在數據庫我們就不談效率了。
駭客攻擊:緩存、數據庫掛掉。
方向三:
分析解釋:降低空間佔用,降低時間消耗。
透過 MD5 算法保存垃圾郵箱,降低空間,使用 HashSet 存儲數據,而 MD5 存在衝突的可能性,儘管概率低。
駭客攻擊:緩存、數據庫掛掉。
方向四:
分析解釋:降低空間佔用,降低時間消耗
bit 數組初始化是所有值均設置為 0。(本質上僅由 0 或 1 組成)
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
|---|
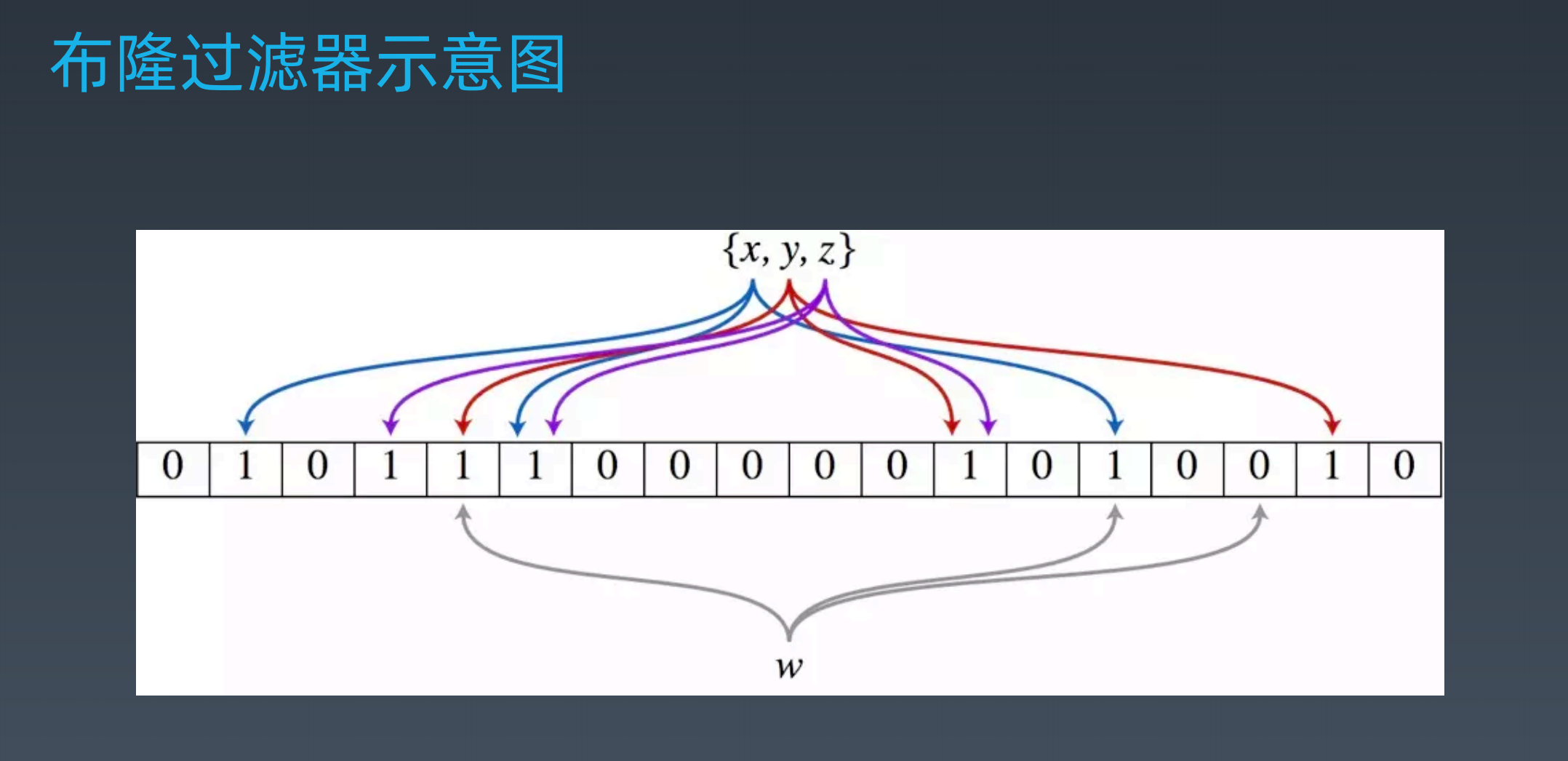
透過上圖,解釋「將所有垃圾郵箱透過多個 Hash 算法,映射到一個 bit數組」
每一個箭頭,就是一個 Hash 函數(先不管 Hash 函數是什麼,那是更深的範疇了)
將數十億的垃圾郵箱(
{x, y, z}),透過 K 個 Hash 函數,並映射到 bit 數組上改為 1 ,改到同一個一樣是 1 (ex: 上圖 X 和 Z 有指向同一個位置,都是改為 1)等到數十億的垃圾郵箱都映射在同一個 bit 數組後,得到一個超大的 bit 數組,相較於 HashSet 佔用空間很小
布隆過濾器
布隆過濾器是一個占用空間很小、效率很高的隨機數據結構,它由一個 bit 數組和一組 Hash 算法構成。
- 邏輯:將參數丟進布隆過濾器,由 Hash 函數計算後比對 bit 數組都符合 1,就返回 true,列為垃圾郵箱(ex: 丟入 x 則為 true, w 則為 false)
- 優點:不會漏報(false Negative),快速區分 true 和 false。
- 缺點:會有誤報(false Positive),僅 true 時會有誤報,當非垃圾郵箱 a 透過 Hash 函數計算後都符合 1 ,而這是一種誤報,屬於少數具備可控、可接受的容錯率,也就是所謂 衝突概率高。(可以參考這篇)
駭客攻擊:完美阻止惡意請求。
結論
其實在過往,用時間換取空間,在大部分時候是好得方案,布隆過濾器,可以在垃圾郵箱訪問緩存、數據庫之前,做到快速區分此數據:
將已知的億筆數據,存儲在 bit 數組,透過布隆過濾器判斷單筆資料是否在此數組裡,返回 true 即可能在億筆數據中,需要二驗數據, 返回 false 即不在此億筆數據裡。
對於 true 是誤判的資料是可控性的,且屬於少數,此時再透過白名單,或驗證資料庫、緩存等操作時也相較快。
布隆過濾器還有一個應用場景就是解決緩存穿透的問題。所謂的緩存穿透就是服務調用方每次都是查詢不在緩存中的數據,這樣每次服務調用都會到數據庫中進行查詢,如果這類請求比較多的話,就會導致數據庫壓力增大,這樣緩存就失去了意義
以代碼表達講解:
1 | bf = BloomFilter.create(億筆垃圾郵箱) |
應用場景
不只是標題,還有許多類似的應用場景
- 網頁爬蟲對 URL 去重,避免爬取相同的 URL 地址
- Google Chrome 使用布隆過濾器識別惡意 URL
- Medium 使用布隆過濾器避免推薦給用戶已經讀過的文章
- Google BigTable,Apache HBbase 和 Apache Cassandra 使用布隆過濾器減少對不存在的行和列的查找
- 比特幣加速 bitcoin 使用布隆過濾器來加速錢包同步
REF
Bloom Filter 是為了解決 Hash table 的空間以及查詢時間,算法本身的原理可以相當快速地判斷某個元素是否有出現在集合,但會有 false positive 的情形出現,因此在 PostgreSQL 當中需要做二次檢查。
布隆过滤器你值得拥有的开发利器 講解布隆过滤器 bit 數組 & 布隆過濾器實戰
在導入 Guava 庫後,我們新建一個 BloomFilterDemo 類,在 main 方法中我們通過 BloomFilter.create 方法來創建一個布隆過濾器,接著我們初始化 1 百萬條數據到過濾器中,然後在原有的基礎上增加 10000 條數據並判斷這些數據是否存在布隆過濾器中:
布隆过滤器实战【防止缓存击穿】 講解為什麼引入,以及布隆過濾器原理
對於BloomFilter的優點來說,缺點都可以忽略。畢竟只需要kN的存儲空間就能存儲N個元素。空間效率十分優秀。
使用BloomFilter布隆过滤器解决缓存击穿、垃圾邮件识别、集合判重
歸根到底意思其實就是你想讓 BloomFilter 錯誤率降低,就得增大數組的長度,就是這樣。
我們使用BloomFilter的目的就是想省空間,所以我們需要做的就是在錯誤率上做個權衡就OK。
在其留言中,艾宾浩斯的美酒:
解决的是缓存穿透,而不是缓存击穿。缓存击穿最通俗的例子:新浪微博热搜,,某个热点5分钟后Redis里面数据过期,然后该新闻不属于热搜,所以缓存失效。
淺談 Java 中的 Set、List、Map 的區別 - 胡忠晞 Jax 透過該文理解 Java
Java 集合主要分為三種類型:
Set(集合)
List(列表)
Map(映射)
我把該文章範例丟到 idenone 玩過幾輪
Bloom Filter - python
Bloom Filter - java
- https://github.com/Baqend/Orestes-Bloomfilter
- https://github.com/lovasoa/bloomfilter/tree/master/src/main
Bloom Filter - ruby